Deep learning for complex image data
- Department Image analysis and Earth observation
- Fields involved Image analysis and Earth observation, Earth observation, Image analysis, Visual Intelligence
Deep learning (DL) has revolutionised computer vision and significantly transformed the fields of image analysis and machine learning. We have been at the forefront of adapting DL for numerous applications and it has been integral to most of our projects in image analysis since 2018.
NR contributes to research and development in image analysis, machine learning, and Earth observation. Our applications are diverse, spanning healthcare, transportation, ocean, climate and environment, infrastructure, and general mapping and monitoring. We use deep learning to analyse complex image data from a range of sources, including ultrasound sensors, MRI machines, echo sounders, seismic sensors, multi-spectral and hyperspectral sensors, and synthetic aperture radar (SAR) satellite sensors.
Deep learning exceeds human performance
Today, deep learning is the leading approach for solving most image analysis problems, often achieving accuracies that surpass human performance. We have successfully applied deep learning to a wide range of real-world applications, with many of our solutions in operational use every day.

Research challenges
Learning and applying deep learning comes with several challenges. Annotating complex image data requires expert knowledge and is both costly and time-consuming. While machine learning methods are data-driven, incorporating human knowledge, constraints and physics is often necessary. To ensure trustworthiness, it is crucial that the models acknowledge their own limitations. Additionally, due to their complexity, the models often lack clarity and transparency during interference.
Our research encompasses the following areas:
- Learning from limited data: Utilising methods such as self-supervised learning to effectively explore seismic data.
- Incorporating context, dependencies and prior knowledge: Enhancing ultrasound analysis by leveraging graphs or improving thematic mapping of coastal habitats from airborne imagery using class hierarchies.
- Estimating confidence and quantifying uncertainties: Developing techniques to estimate pixel-wise uncertainty in snow maps.
- Understanding predictions: Providing explanations for predictions, such as age estimates of fish.
Visual Intelligence
These challenges are also central to Visual Intelligence, a Center for Research-based Innovation (SFI). This centre is a collaborative effort involving the host institution, UiT The Arctic University of Norway, NR and the University of Oslo (UiO). Together, we are committed to research-driven innovation, focusing on adapting and applying deep learning to complex image data, in partnership with a number of user groups.
We also actively support related research areas such as:
- AI for small devices and large GPU-clusters,
- super-resolution and generative AI,
- multimodality – integrating text, images and other data,
- foundation models for handling complex data.
Learning from limited data
Deep learning methods steadily improve as more training data becomes available. However, in practical applications like medical and satellite imaging, obtaining high-quality annotated data is a significant challenge. Annotations are important as they provide labels to guide the learning process, but they are often incomplete or inconsistent. Furthermore, the annotations have typically been made for purposes other than training machine learning models, which can make them less suitable for this purpose.
In response to these challenges, our research explores innovative methods such as self-supervised learning, leveraging weak labels and domain adaptation. These strategies can help train our models effectively, even when handling suboptimal datasets.

Understanding deep learning predictions
It is not always clear why a deep learning model makes a specific prediction. While the models typically work well across a range of scenarios, they can make mistakes that seem odd or are even harmful. Understanding the models’ behaviour is crucial, especially when applied in sensitive areas such as healthcare and industry.
At NR, our research focuses on developing methods that can explain predictions and accurately estimate the uncertainty associated with them. For example, our recent work in breast cancer screening involved explainability analysis to determine which parts of an image most significantly influence the model’s decision to identify a tumour.
Incorporating dependencies and prior knowledge
Machine learning excels by learning directly from data, rather than using pre-defined models. However, processing complex data requires a combination of traditional machine learning and physical or geometrical models. This integrated approach allows us to include prior knowledge and dependencies and manage multiple types of complex images at the same time.
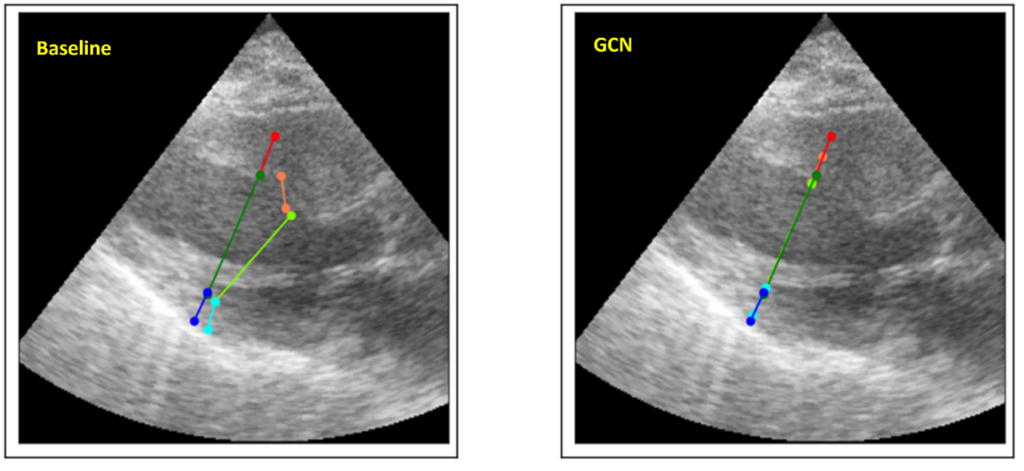
Despite their strengths, many deep learning models struggle to incorporate context and prior knowledge, such as topological or physical properties. We are researching methods to address these limitations. One example is our exploration of graph convolutional networks (GCN) as a way to model the relative positions of key features in medical images.
Estimating confidence and uncertainties in predictions
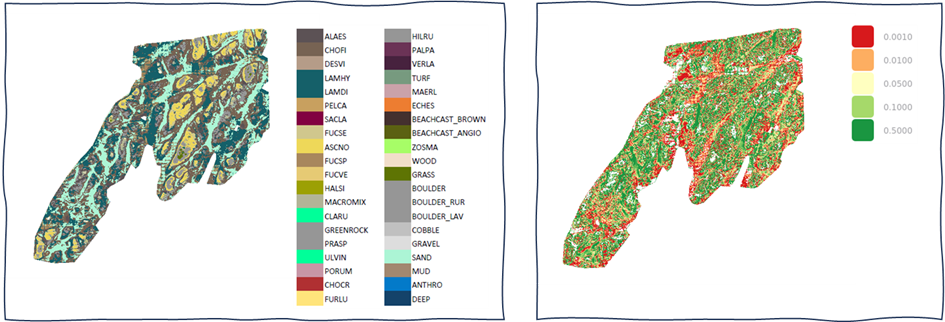
Deep neural networks are powerful predictive models, but they sometimes fail to recognise erroneous predictions or whether the input data falls outside their reliable range. For critical or automatic applications wherein mistakes may have serious consequences, this understanding is essential. For example, in our coastal habitat mapping projects, our approach not only classifies data but also provides maps conveying prediction credibility.
AI for small devices and large GPU clusters
Deep neural networks require substantial computing power. At NR, we develop models that cater to a range of hardware configurations. For clients requiring models that can operate on battery-powered devices like those used in edge AI, we prioritise compactness and efficiency. For others, we may develop models that can leverage the power of large GPU clusters, maximising performance on multiple computers. As a leading institute in computer science, we ensure our models and their corresponding data pipelines are optimised for suitability and efficiency on any given platform.
Super resolution and generative AI
Diffusion models are transforming how we generate images, from everyday objects and scenic landscapes to creating realistic human faces. We use these models to improve the resolution of satellite images. This process is known as super resolution and is particularly well-suited to these types of images. High-resolution satellite images are vital to environmental monitoring, urban planning and disaster management. By improving image clarity, diffusion models provide decision-makers with more precise data, thereby enhancing both analysis and decision-making processes.

Combing text, images and other data
Deep learning models are versatile and can process various types of data at the same time, including images, text, audio and additional metadata. This capability enables the development of models that can, for example, generate textual descriptions from images. We harness this technology to provide comprehensive solutions for clients who need to analyse different types of data related to the same phenomena.

Foundation models
Training deep learning models typically requires extensive data with detailed annotations, a process that is often expensive and time-consuming. Recent advancements like self-supervised learning have begun to address these challenges. One example is training models on partially hidden data and subsequently training the models to reconstruct the data that has been concealed. This approach helps models develop an understanding of the data without prior annotation. Known as foundation models, these systems form a base that can be further refined in order to solve specific tasks. Importantly, these models can be trained with much less data than previously required. At NR, we not only leverage existing foundation models but also train new ones for types of data where none currently exist.
To learn more about deep learning for complex image data, please contact:


Research centres
We are part of Visual Intelligence –
a Centre for Research-Based Innovation hosted by UiT The Arctic University of Norway.

Publications
Brautaset, O., Waldeland, A. U., Johnsen, E., Malde, K., Eikvil, L., Salberg, A.-B., & Handegard, N. O. (2020). Acoustic classification in multifrequency echosounder data using deep convolutional neural networks. ICES Journal of Marine Science, 77(4), 1391-1400. https://doi.org/10.1093/icesjms/fsz235
Gilbert, A. D., Holden, M., Eikvil, L., Aase, S. A., Samset, E., & McLeod, K. (2019). Automated left ventricle dimension measurement in 2D cardiac ultrasound via an anatomically meaningful CNN approach. In Smart Ultrasound Imaging and Perinatal, Preterm and Paediatric Image Analysis: First International Workshop, SUSI 2019, and 4th International Workshop, PIPPI 2019, Held in Conjunction with MICCAI 2019, Shenzhen, China, October 13 and 17, 2019, Proceedings (pp. 29-37). Springer International Publishing. https://doi.org/10.48550/arXiv.1911.02448
Gilbert, A. D., Holden, M., Eikvil, L., Rakhmail, M., Babic, A., Aase, S. A., Samset, E., & McLeod, K. (2021). User-intended Doppler measurement type prediction combining CNNs with smart post-processing. IEEE Journal of Biomedical and Health Informatics, 25(6), 2113-2124. https://doi.org/10.1109/JBHI.2020.3029392
Kampffmeyer, M., Salberg, A.-B., & Jenssen, R. (2016). Semantic segmentation of small objects and modeling of uncertainty in urban remote sensing images using deep convolutional neural networks. In 2016 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Las Vegas. https://doi.org/10.1109/CVPRW.2016.90
Liu, Q., Kampffmeyer, M., Jenssen, R., & Salberg, A.-B. (2021). SCG-Net: Self-constructing graph neural networks for semantic segmentation. International Journal of Remote Sensing, 42(16), Article 2021. https://doi.org/10.48550/arXiv.2009.01599
Thorvaldsen, G., Pujadas-Mora, J. M., Andersen, T., Eikvil, L., Lladós, J., Fornés, A., & Cabré, A. (2015). A tale of two transcriptions: Machine-assisted transcription of historical sources. Historical Life Course Studies, 2, 1-19. https://hlcs.nl/article/view/9355/9854
Trier, Ø. D., Salberg, A.-B., & Pilø, L. (2018). Semi-automatic mapping of charcoal kilns from airborne laser scanning data using deep learning. In CAA2016: Oceans of Data. Proceedings of the 44th Conference on Computer Applications and Quantitative Methods in Archaeology (pp. 219-231). Oxford: Archaeopress. https://doi.org/10.1016/j.jag.2020.102241
Waldeland, A. U., Trier, Ø. D., & Salberg, A. (2022). Forest mapping and monitoring in Africa using Sentinel-2 data and deep learning. International Journal of Applied Earth Observation and Geoinformation, 111, Article 102840. https://doi.org/10.1016/j.jag.2022.102840
Selected projects