Marin bildeanalyse
- Avdeling Bildeanalyse og jordobservasjon
- Involverte fagområder Bildeanalyse
Hver dag genereres store mengder observasjonsdata som brukes til overvåkning og ressursforvaltning i marin sektor. Disse dataene inneholder verdifull informasjon som er avgjørende for bærekraftig fiskeri og havbruk, men manuelle metoder er ikke tilstrekkelige for å håndtere datamengdene eller komplektiseten. På NR utvikler vi metoder basert på dyp læring som automatiserer innsamling, oppdaging og klassifisering av data som bidrar til å gjøre disse prosessene mer effektive, presise og skalerbare.

Effektiv analyse av komplekse marine data
De store volumene med observasjonsdata i marin sektor er ofte svært komplekse og kommer i mange ulike formater, som undervannsvideoer, sonarakustikk, dronebilder og mikroskopiske bilder. Dataene brukes til viktige oppgaver som overvåkning av bestander og økosysystemer, kartlegging av sjøpattedyr og sikring av bærekraftige fangstkvoter.
Datamengdene forventes å øke betydelig, særlig etter hvert som sanntidsanalyser blir mer utbredt. Dette gjør manuelle metoder stadig mindre effektive. Dyp læring tilbyr løsninger som kan håndtere disse utfordringene på en effektiv måte.
Automatisert sporing av fiskebestander
Undervannskameraer brukes i økende grad til å overvåke fiskebestander. Kameraene kan plasseres i tråler, oppdrettsanlegg eller nær marine leveområder. Manuell analyse av dataene er kostbar, tidkrevende og lite effektiv. Ved hjelp av metoder basert på dyp læring kan fisk i undervannsvideoer automatisk oppdages, identifiseres og spores over tid.
Det er likevel utfordringer knyttet til slike bildedata, som komplekst innhold og struktur, samt begrenset tilgang til treningsdata. I samarbeid med Havforskningsinstituttet utvikler vi derfor metoder som forbedrer og effektivserer informasjonsuttrekk av marine bildedata.
Deteksjon og klassifisering av marine data
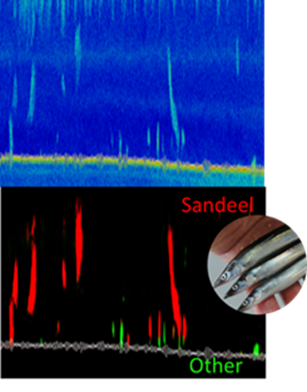
Den sammensatte naturen til marine bildedata og mangelen på treningsdata er utfordrende. For eksempel er akustiske trålundersøkelser ofte ikke merket med detaljerte annoteringer. Vi har utviklet en metode for å oppdage og klassifisere havsil ved bruk av sterkt merkede akustiske data, og vi jobber nå med å tilpasse denne metoden for svakt merkede data.
For å forbedre prediksjoner i havbrukssektoren er det også vanlig å kombinere data fra ulike kilder. Vi har derfor utvidet havsilmodellen til å inkludere tilleggsdata med ulike datatyper, noe som har forbedret modellens ytelse betraktelig.
Forklarbar kunstig intelligens for økt transparens
Når data brukes som grunnlag for prediksjoner, som ved bestandsestimering, er pålitelighet, transparens og etterprøvbarhet avgjørende. Forklarbar kunstig intelligens (XAI) gir verktøy som gjør det mulig å forstå hvordan modeller tar beslutninger.
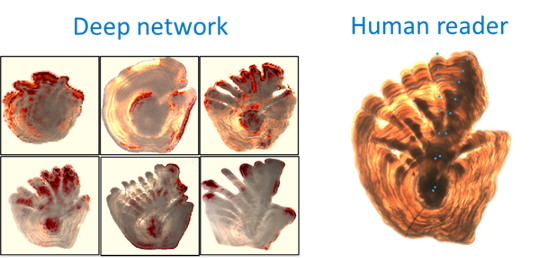
Vi har blant annet brukt XAI til å undersøke hvilke deler av otolitter modellene fokuserer på når de estimerer fiskens alder. Videre har vi forsket på hvordan modellens presterer på nye datasett med ulike fordelinger. For eksempel har vi oppdaget at ytelsen kan variere når otolittbildene stammer fra ulike laboratorier. Vi undersøker nå metoder for tilåpasning mellom datasett som gjør det mulig for modeller trent på data fra ett laboratorium å presetere like godt på data fra andre, uten behov for ytterlige trening.
Utvalgte prosjekter

Vil du vite mer om arbeidet vårt innen marin bildeanalyse?
Ta kontakt:

Partner: Havforskningsinstituttet (HI)